📏RULER: Relative Universal LLM-Elicited Rewards
RULER (Relative Universal LLM-Elicited Rewards) is a general-purpose reward function that uses an LLM-as-judge to rank multiple agent trajectories. It requires no labeled data, expert feedback, or hand-crafted reward functions, yet reliably improves agent performance.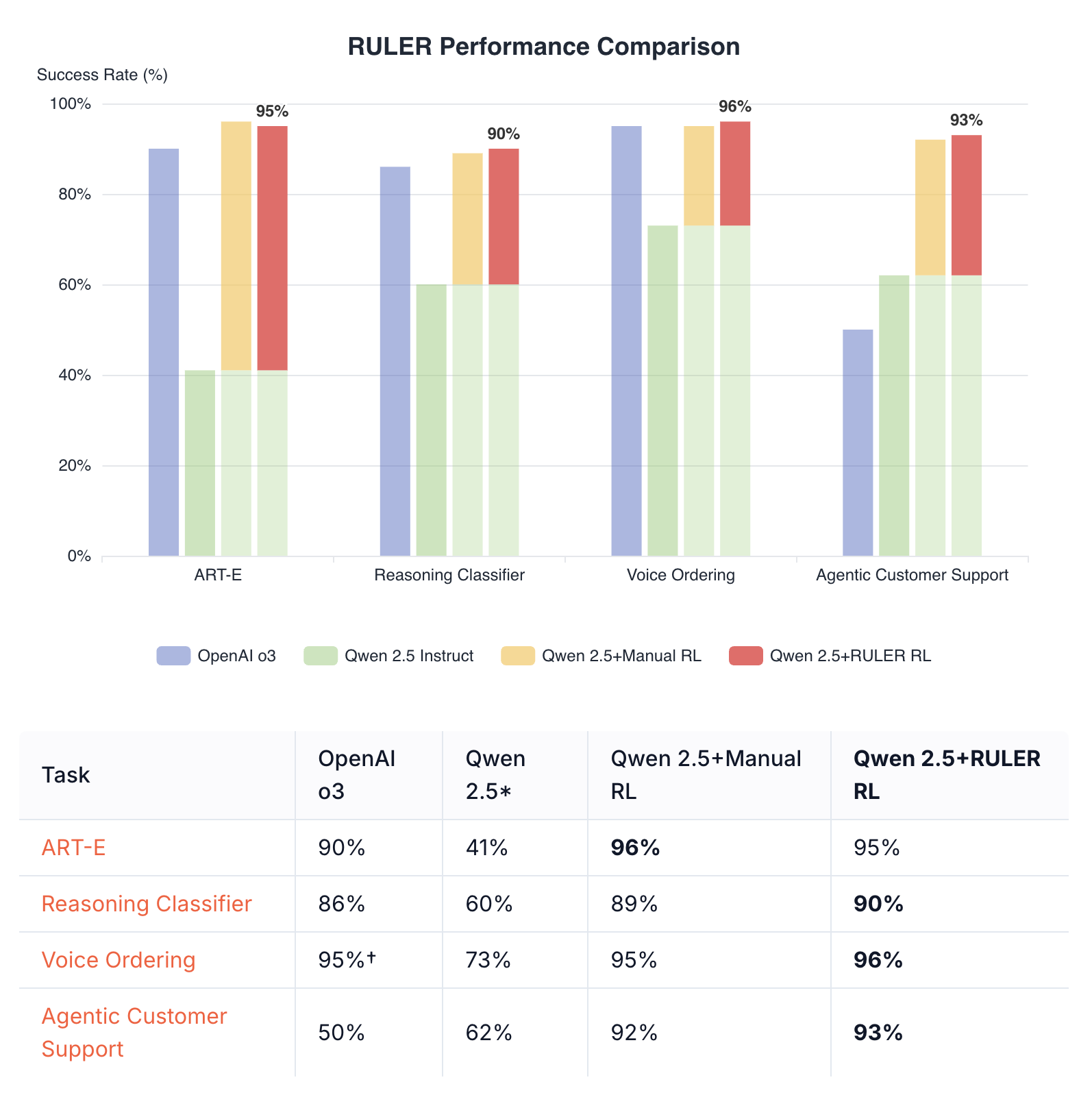
Key Benefits
- No labeled data required: RULER works by comparing trajectories against each other
- General-purpose: Can be applied to a wide variety of RL tasks without modification
- Fast development: Can reduce implementation time by 2-3x compared to hand-crafted rewards
- Strong performance: Often matches or exceeds hand-crafted reward functions
How RULER Works
RULER leverages two key insights:- Relative scoring is easier than absolute scoring: It’s easier for an LLM to rank several solutions relative to each other than to score them in isolation
- GRPO only needs relative scores: Since GRPO normalizes scores within each group, only the relative rankings matter, not absolute values
- Generate N trajectories for a given scenario
- Pass all N trajectories to RULER
- RULER deduplicates common prefixes (e.g., identical system messages)
- An LLM judge scores each trajectory from 0 to 1 based on goal achievement
- These scores are used directly as rewards in GRPO training
Basic Usage
Complete Example: Joke Generation
Here’s a toy example showing how RULER ranks different quality trajectories:Example Output
Customization
Judge Model
You can use any LLM supported by LiteLLM as the judge:Extra LiteLLM Parameters
You can pass additional parameters to LiteLLM for fine-tuning the judge behavior:Custom Rubric
While the default rubric works well for most tasks, you can provide a custom one:Using Raw Message Lists
If you’re not usingart.Trajectory objects, you can use the lower-level ruler function:
Best Practices
- Clear system prompts: RULER uses the system prompt to understand the agent’s goal. Make sure your system prompts clearly describe what the agent should do.
- Group size: Use 4-8 trajectories per group for optimal balance between diversity and cost. Very large groups are not recommended because they can confuse the judge.
-
Debug mode: Enable
debug=Trueto see the judge’s reasoning, which helps identify scoring patterns. - Judge selection: Cheaper models like Qwen3 32B often work well and are more cost-effective than larger models.
Integration with Training
RULER integrates into ART’s training loop using thegather_trajectory_groups helper with an after_each callback:
swallow_exceptions=True parameter is recommended in production to handle judge API failures gracefully - groups that fail to be judged are simply filtered out rather than crashing the training loop.
Combining RULER with Independent Rewards
While not usually necessary, RULER can be easily combined with other reward functions that judge trajectories independently. You can calculate independent rewards before applying RULER during the rollout function, or calculate and combine them afterward. Either of these approaches allow you to combine hand-crafted rewards with RULER’s general-purpose scoring.Preserving Original Rewards
If you assign rewards within your rollout function, RULER preserves them under the “independent_reward” metric:Adding Independent Rewards After Judging
Additionally, you can adjust rewards after callingruler_score_group:
Performance Tips
- Caching: RULER automatically caches judge responses to disk to avoid redundant API calls
- Batch processing: Process multiple groups in parallel when possible
- Token efficiency: Common prefixes are automatically deduplicated to save tokens
Troubleshooting
Low scores for all trajectories
- Check that your system prompt clearly defines the task
- Ensure trajectories are actually attempting the task
- Try the default rubric before customizing
Inconsistent rankings
- Increase group size for more stable relative rankings
- Use a more capable judge model
- Add more specific criteria to your rubric
High API costs
- Use cheaper judge models (e.g., Qwen3 32B)
- Reduce group size
Since RULER uses LiteLLM under the hood, ART automatically suppresses harmless Pydantic serialization warnings from LiteLLM (related issue). To disable this behavior, set
SUPPRESS_LITELLM_SERIALIZATION_WARNINGS=0 in your environment.