What is ART?
What is ART?
ART (Agent Reinforcement Trainer) is a reinforcement learning framework that
allows for easy training of LLM-based agents using GRPO (as well as PPO and
other techniques in the future). It’s focused on best-in-class training
efficiency ergonomic agentic multi-turn support.By allowing an LLM to make multiple attempts at accomplishing a task and scoring each rollout’s performance, we shift the model’s weights to make it more likely to perform the way it did in its best runs and to avoid its least effective behavior.
Can I start RL from an existing SFT LoRA adapter?
Can I start RL from an existing SFT LoRA adapter?
Yes. If you have a standard Hugging Face–style LoRA adapter directory (e.g., produced by Unsloth/PEFT), pass the adapter folder path as the ART will load the adapter as the initial checkpoint and proceed with RL updates from there.
base_model when creating your TrainableModel.How does ART work under the hood?
How does ART work under the hood?
This flow chart shows a highly simplified flow of how ART optimizes your agent. Your code is responsible for actually running the agent in the environment it will operate in, as well as scoring the trajectory (deciding whether the agent did a good job or not). ART is then able to take those trajectories and scores and use them to iteratively train your agent and improve performance.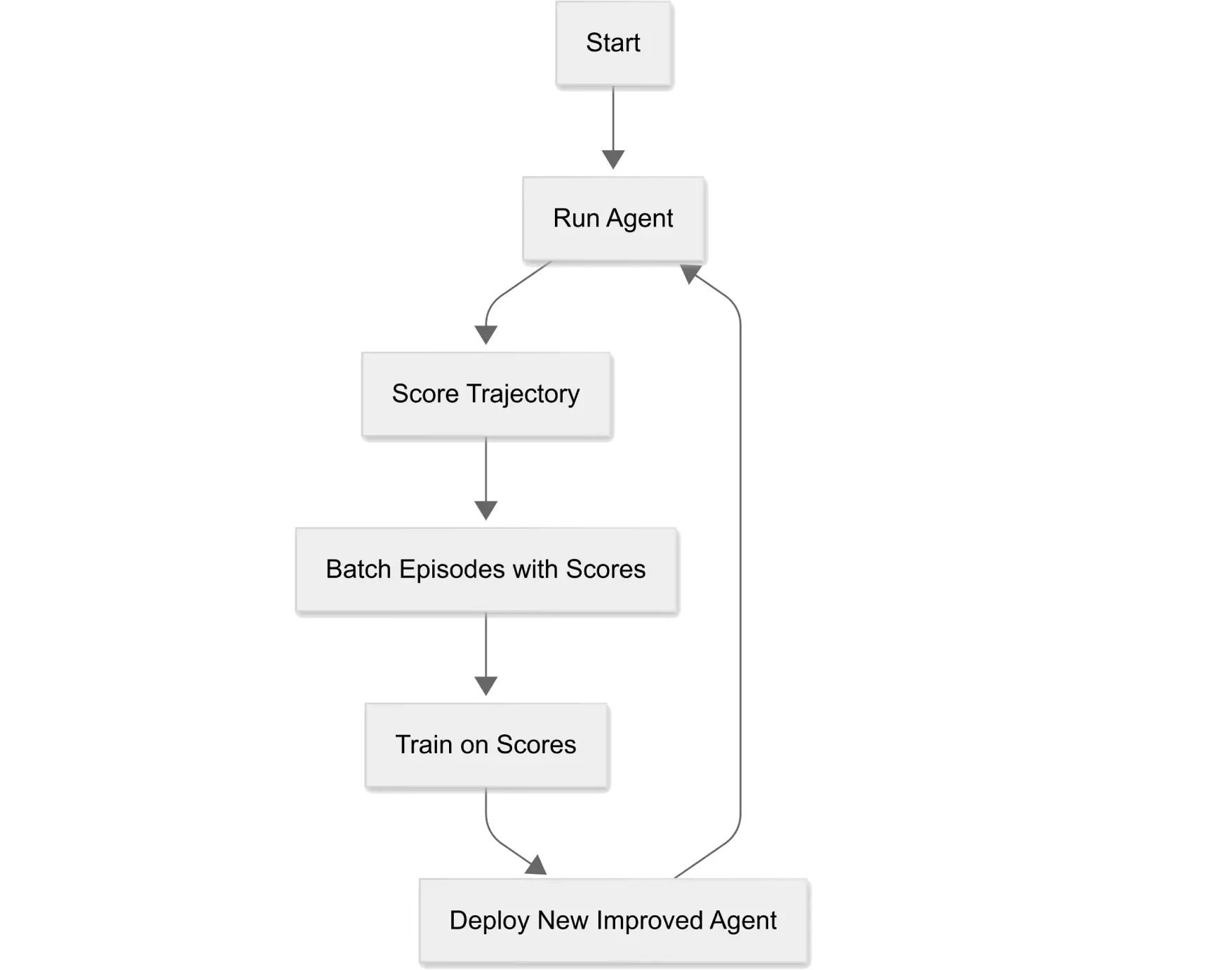
Why separate frontend from backend? Doesn't that increase complexity?
Why separate frontend from backend? Doesn't that increase complexity?
By separating the ART backend into a separate service, we’ve been able to keep
the ART frontend extremely narrow and clean. This makes it much easier to
embed it into existing production applications, while allowing the heavy
backend to be run on separate, powerful machines with appropriate GPU
resources. We’ve included an open-source ART backend and over time we expect
more providers to implement hosted ART backends as well, giving users choice
and convenience in where their models are trained. Note however that the
initial release assumes that the frontend and backend are running on the same
machine with a GPU available.
How do I know whether ART can help my agent improve performance?
How do I know whether ART can help my agent improve performance?
To get good results with ART, we recommend first ensuring your task meets the following requirements:
- Open source models can complete the task at least 30% of the time already. If you try to use ART on a task that is too far out of distribution, it likely won’t be able to teach your model efficiently.
- You can easily verify whether a task was completed successfully. ART, like all reinforcement-learning approaches, works by training a model to maximize a reward. To use it successfully, you need to be able to define some kind of quantifiable reward for the model to optimize against. Rewards can be objective (“does this output match the golden data from my training set”) or subjective (“does this output satisfy my LLM-as-judge”) but must be consistent and quantifiable.
- Your agent can be run many times without affecting the real world. ART currently builds on GRPO, an RL algorithm that involves running many agents in parallel and then using the difference in the rewards they achieve as a stable training signal. This means that you need to be able to run the model many times in the same scenario as part of training, which isn’t a good fit for agents that make changes in the external world.
Which pieces of ART are open source?
Which pieces of ART are open source?
We are committed to maintaining ART as a full-featured open source project. We
will also deploy an optional hosted ART backend for users who don’t want to
manage GPU infrastructure on their own.
How expensive are ART training runs?
How expensive are ART training runs?
RL can often be more expensive than other training methods like SFT for a
given dataset size. In our experiments, training runs often cost between 200 in GPU time. We are actively working on improving efficiency and
welcome contributions in this area; there is still a lot of low-hanging fruit
to pick here.
Can I use ART to train on user feedback in production directly?
Can I use ART to train on user feedback in production directly?
This is theoretically possible, and an area that we’re interested in
exploring! However, there are practical challenges that make this a bit of a
longer-term project. For now, we recommend training a reward model on your
production feedback, and then using ART to optimize your model or agent
against that reward model.
Is ART just for agents? I'm interested in training a non-agentic model with RL.
Is ART just for agents? I'm interested in training a non-agentic model with RL.
We designed the ART architecture to make training agents trivial. But under
the hood we are using GRPO, which is a general purpose RL technique and the
same one used to train R1, the frontier open-source reasoning model. ART is
very effective at optimizing any LLM task for which you can define a
quantifiable reward signal.