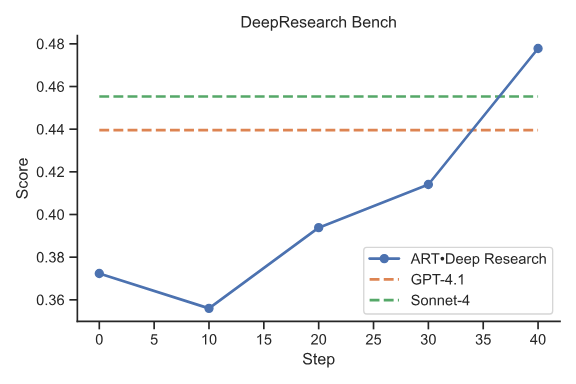
Accuracy of a Qwen2.5 14B Instruct model (the same model you will be training) as it learns to perform deep research, eventually exceeding the performance of GPT-4.1 and Sonnet 4.
Reading time: 45 minTraining time: 30 hrTotal cost: ~$350
Step 1: Clone the starter repo and install dependencies
To get started, clone Open Deep Research Training, which contains the following pieces of our RL pipeline:- The deep research agent environment
- The reward function based on DeepResearch Bench
- SFT and GRPO training scripts
- Evaluation benchmarks
uv by following the instructions here.
Then install the project dependencies by running uv sync.
Step 2: Install backend dependencies and provision a GPU
You’ll be usingLocalBackend to manage the GPU that your model will be trained on. Install ART with the backend dependencies:
Step 3: Set up optional environment variables found in .env.example
Copy .env.example to .env at the root of the repository, and fill in the values for the environment variables. If you’re unsure about any of the values, refer to ENV_INSTRUCTIONS.md.
Step 4: Run the training scripts
You’ll want to run these scripts in this order:- Spin up a cluster with 1 or more H200 GPUs.
- This usually takes about 10 minutes, but RunPod occasionally has network throughput issues that can cause the cluster to take up to 30 minutes to spin up.
- Register the model with ART.
- This usually takes less than 5 minutes, though it can require up to 30 minutes if RunPod experiences network issues.
- Download the model checkpoint.
- Usually takes a few minutes depending on the model size.
- Train the model for a specified number of steps.
- Each RL step involves running the research agent on a subset of benchmark questions, and updating the model based on the rewards. We hold out another randomly-selected subset of 10 questions (10% of the total benchmark) that are never used in training that we run evaluations on every 10 steps to make sure the model is still making progress. Training time depends on the number of steps and the complexity of each research task.
- Upload the final model checkpoint.
- This usually takes a few minutes.
Step 5: Generate the benchmarks
Run the benchmark script to evaluate your trained models:- Run each benchmarked model through the DeepResearch Bench evaluation
- Compare performance against baseline models (GPT-4.1, Sonnet 4, etc.)
- Generate accuracy metrics and detailed results
display_benchmarks.ipynb notebook to visualize the results and generate comparison charts.
Step 6: Shutting down your GPU instance
When you’re done training and running benchmarks, shut down your GPU instance through your cloud provider’s console or CLI. If you’re running locally, you can stop the training process.Training Results
After completing the full training pipeline, you should see results similar to the chart at the beginning of this tutorial. The trained model typically shows:- Improved accuracy on research questions compared to the base model
- Better structured research approaches
- More comprehensive information gathering
- Higher quality synthesis of research findings
Next Steps
Your model is trained and portable! Upload it to any platform you choose, including HuggingFace and inference providers like Together and Fireworks. To learn more about ART, check out another tutorial or look through our notebooks! As always, the ART Discord is a great place to ask questions and share results!Summary RL (Tutorial)
Train a summarizer model to outperform Sonnet 4 and GPT-4.1.
ART Notebooks
Train a variety of agents in free Colab notebooks.